Взаимосвязь понятий «уровень значимости», достоверность и ошибка первого рода
При работе со статистическим отчетом, научной статьей или диссертацией Вы постоянно сталкиваетесь таким термином, как уровень значимости или альфа (ошибка первого рода), чаще всего этот уровень задается относительно 5% или вероятности р=о,05. Решение о достоверности различий или «статистически значимых различиях» принимается относительно этого порогового значения. В данной статье мы предлагаем читателю разобраться в том, почему так важен этот уровень и что он значит в практическом смысле.
Определение (словарь Дж. М. Ласта): ОШИБКА ТИПА I (ERROR TYPE I; син. alpha-error — ошибка альфа) ошибочное отклонение нулевой гипотезы, т.е. утверждение о том, что различия существуют, тогда как их нет.
Если вам нужно провести статистический анализ для диссертации или клинического исследования — наши биостатистики помогут с расчётами и интерпретацией результатов. [Подробнее об услуге статистического анализа здесь →]
Немного о смысле уровня значимости и достовернности различий
Для понимания темы статистических ошибок мы перейдем к простейшей матрице соотношения статистики (что она нам говорит по результатам статистических тестов) и реальности. Так вот, предположим, что статистика нам говорит о существовании связей, о существовании различий. В реальности же они также существуют, тогда мы считаем этот результат правильным положительным или truth positive (ТР). Например, статистика нам говорит об отсутствии связей, об отсутствии различий, а в реальности же они действительно существуют. Такая ситуация называется ложноотрицательной или false-negative (FN). Соответственно существуют ситуации, когда статистика нам говорит о существовании каких-то определенных взаимосвязей или о существовании различий, которые в реальности не существуют. Тогда это называется ложноположительной или false-positive (FP). И последний случай касается отсутствия по данным статистических тестов того, чего в действительности не существует, различий в действительности нет. И эта ситуация именуется как truth negative (TN) или ложноотрицательный результат.
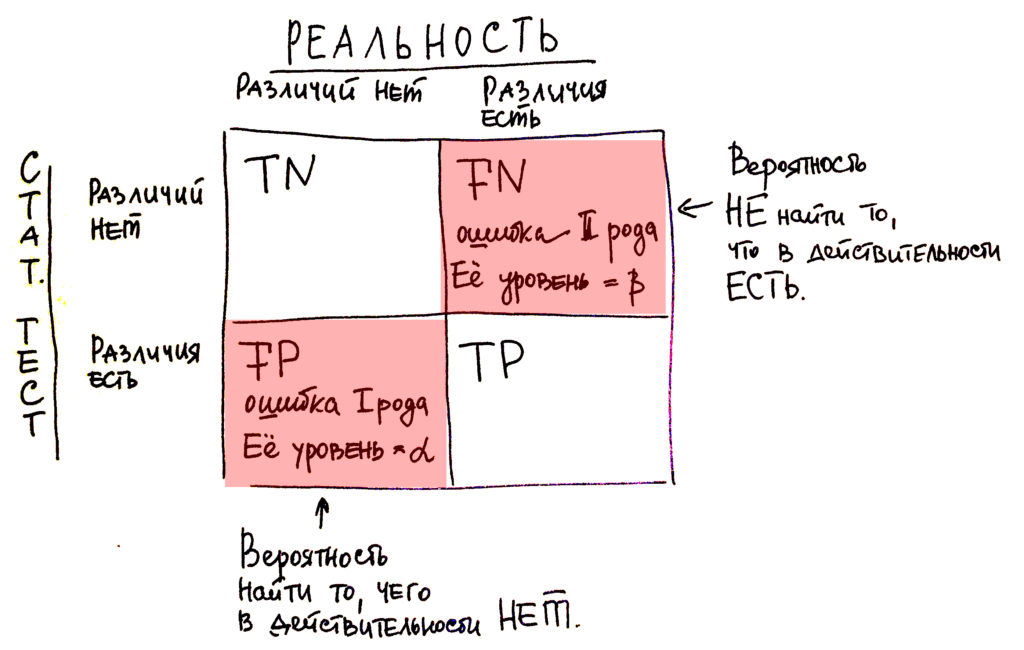
Рисунок 1. Матрица соотношения реальность-результаты статистического теста. TN (true negative) — верноотрицательный, FN (false negative) — ложноотрицательный, FP (false positive) — ложноположительный, TP (true positive) — верно позитивный.
Так вот, как видно из этой матрицы, у нас существуют 2 ситуации, в которых мы можем ошибаться: это false-positive и truth negative. Это как раз два типа ошибок, о которых я говорил в начале этого блока: о ложноотрицательной ошибке и ложноположительной. Что на самом деле это значит?
Что в какой-то ситуации мы можем пересмотреть, а в какой-то – недосмотреть.
Пересмотреть, то есть найти то, чего в действительности нет, это является false-positive – это ошибка первого рода.
Или недосмотреть, то есть упустить то, что в действительности существует в реальности, но по данным статистических тестов мы чего-то не находим – это ложноотрицательный результат или ошибка второго рода.
Давайте нанесем те термины, которые, возможно, вы уже слышали – «уровень достоверности», «достоверные различия». Что это за слово такое «достоверность»? Оно относится как раз к ошибке первого рода и обозначается буквой α. Вы наверняка знаете обозначение уровня в р=0,05. Уровень достоверности в 0,05 как раз является критическим значением для результатов большинства статистических тестов ( 5 %). Мы делаем вывод относительно этих 5 %. Что в практическом смысле это значит? Что в 95 % мы находим различия, которые действительно существуют, и в 5 % даем себе возможность переобнаружить то, чего в действительности не существует в реальности.
Что касается ошибки второго рода, то здесь это уже не 5 %. И мы задаем либо 20, либо 10 %, что-то в этом диапазоне, это ошибка в 0,2; в 0,1. И как раз мы подходим к следующему чрезвычайно важному статистическому понятию как «мощность исследования». Мощность исследования это: (1 – β), где β это ошибка второго рода. Если стандартный уровень ошибки это 0,2 и 0,1, то мы получаем, что мощность исследования в норме составляет 0,8 или 0,9 (чаще, конечно, 0,8).
NB! по уровню значимости
Уровень значимости, то есть ошибки первого рода составляет чаще всего относительно уровня в 5 %, это уровень той ошибки, при которой мы даем возможность себе «перенайти» то, что в действительности не существует. В ошибке второго рода мы даем себе определенный люфт до 20 % не обнаружить того, что в действительности существует, то есть когда статистические тесты нам скажут, что чего-то нет, а в реальности эти различия существуют.
Автор: Кирилл Мильчаков
Нужна помощь со статистикой? Мы делаем анализ данных для медицинских исследований под ключ. [Узнать стоимость →]