Доверительный интервал за 15 минут
Добрый день, уважаемые читатели!
Меня зовут Кирилл Мильчаков. Сегодня мы продолжаем наш разговор о биостатистике. Тема сегодняшней нашей беседы будет «Доверительный интервал». Что такое доверительный интервал? Вы наверняка встречались с ним в научной литературе. Доверительный интервал 95 %, либо сочетание символов ДИ и CI (confidence interval) 95 %. Что же означают эти 95 %? Какие он еще может принимать значения? И как его рассчитывать самостоятельно? Об этом обо всем сегодня мы и поговорим в этой статье.
Видео-версия статьи о доверительном интервале
Генеральная совокупность и выборочная совокупность
Прежде чем углубляться в тайны доверительного интервала, хотел бы вспомнить с вами 2 основных понятия статистической совокупности, с которыми чаще всего работают – это генеральная совокупность или выборочная совокупность или выборка.
Генеральная совокупность – это тот массив данных, о которых вы хотите сделать выводы.
Выборка является частью генеральной совокупности, которая участвует непосредственно в вашем эксперименте. Есть такое понятие как репрезентативность, сегодня мы не будем его касаться, главное запомнить, что выборка должна быть репрезентативной.
Если привести небольшой пример относительно генеральной совокупности и выборки, то можно вспомнить о простом случае из вашей жизни. Когда вы хотите узнать, достаточно ли посолен суп, вы берете ложку супа и пробуете его. Вам необязательно есть весь суп, чтобы понять, насколько он посолен. Ложка в данном случае является выборкой, по которой вы делаете вывод обо всей кастрюле супа. В данном случае кастрюля супа является генеральной совокупностью, а ложка супа является выборкой.
Итак, мы вспомнили с вами о 2 ключевых статистических совокупностях – о генеральной совокупности и выборочной совокупности. Теперь нужно вспомнить, что типы исследования, которые проводятся над генеральной совокупностью и выборочной совокупностью, называют по-разному. Над генеральной совокупностью проводятся так называемые сплошные исследования, над выборочной совокупностью – выборочные.
Теперь вспомним небольшие отличия между параметрами этих 2 совокупностей. Сегодня для того, чтобы понять, что такое доверительный интервал, нам понадобятся следующие вещи: во-первых, отличие средней арифметической в генеральной совокупности и в выборочной совокупности. В генеральной совокупности она имеет значок µ (мю), в выборочной – это x̅ (х с чертой) — это средние арифметические по каждому виду совокупности.

Далее нужно знать, что стандартное отклонение имеет значок выборочной – либо S, либо SD (standard deviation), а в случае генеральной совокупности оно носит название среднеквадратичного отклонения и обозначается буквой σ (сигма).
Приведем пример расчета доврительного интервала
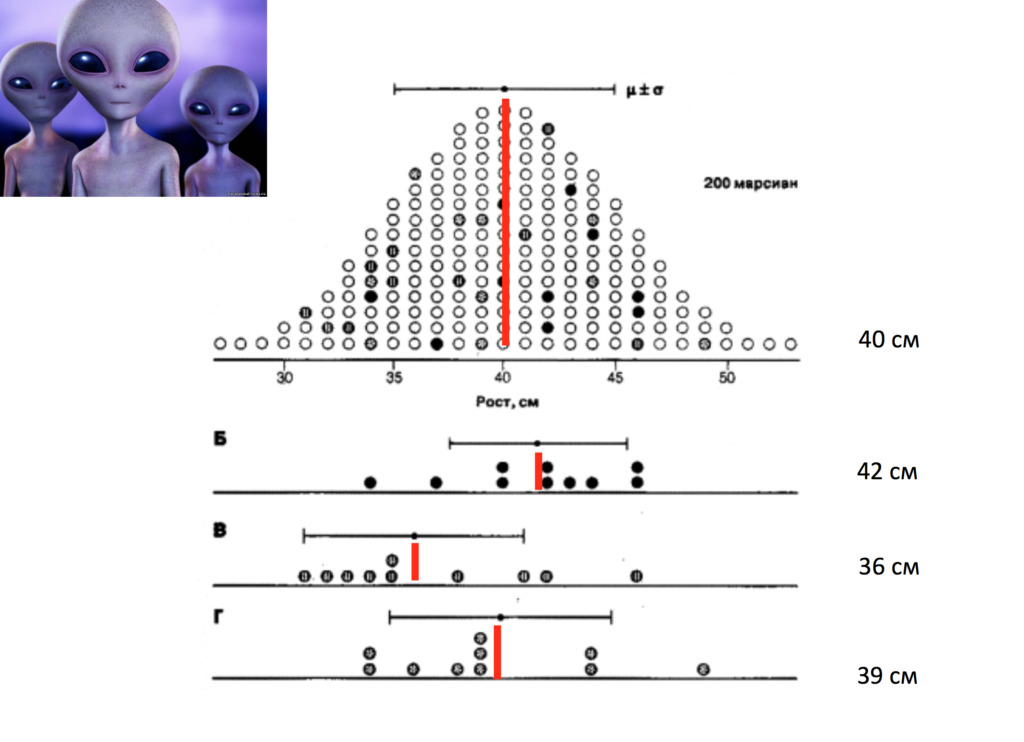
Представьте чисто гипотетическую ситуацию, когда перед нами стоит задача исследований среднего роста марсианина. Для того, чтобы его узнать, было отправлено 3 экспедиции. Первой из них повезло больше всего: они смогли поймать каждого из 200 марсианин и померить его рост.
Как мы помним, по закону нормального распределения по оси Х находится величина изучаемого признака, либо варианта (в данном случае это рост в сантиметрах), а по оси Y – частота встречаемости какого-то признака (мы его обозначаем буквой П.
Итак, оказалось, что у всех 200 марсиан средний рост составил 40 сантиметров. Таким образом, первая экспедиция смогла провести так называемое сплошное исследование, так как поработала со всеми единицами наблюдения генеральной совокупности. Поэтому мы имеем право назвать этот параметр µ.
Однако, второй и третьей экспедиции повезло гораздо меньше. Они попали в самые плохо населенные участки Марса и смогли отобрать только 10 марсиан. В данном случае оказалось, что средний рост по их выборке составил всего 38 сантиметров в первом случае и 41 сантиметр во втором случае.
Что же делать? Да, у нас есть данные из самого полного исследования, которое относится к первой экспедиции. Но представьте, что ни одна бы из них не смогла бы поработать со всей совокупностью полностью, и у нас были бы данные только от второй и третьей экспедиции. Что же в этой ситуации делать? Видно, что никто 40 сантиметров в действительности не достиг: во второй экспедиции Б она равна 38 сантиметрам, а в экспедиции В – 41 сантиметр. То есть в реальности никто не достиг 40 сантиметров. Что же делать в данном случае?
И вот здесь на помощь к нам приходит доверительный интервал, точнее оценка параметра. Доверительный интервал является вторым этапом оценки параметра. Прежде чем строить доверительный интервал, нам нужно понять, насколько в принципе этот параметр наша средняя (x̅б, x̅в) может отличаться, ошибаться от реального параметра в генеральной совокупности. Насколько?
И тут нам помогает оценка параметра или нахождение ошибки репрезентативности. Ошибка репрезентативности обозначается mr или mx. Чаще я использую mr. Что же это значит? mr по-английски обозначается как standard error, по-русски она часто называется стандартная ошибка средней или ошибка репрезентативности. Как же она находится? А находится она следующим образом? Она учитывает стандартное квадратичное отклонение в генеральной совокупности и размер в выборке. От чего же зависит ошибка репрезентативности? А зависит она от 2 вещей: от среднеквадратичного отклонения в генеральной совокупности (я напоминаю, это насколько каждая варианта отличается от средней, о законе нормального распределения мы с вами поговорим в следующий раз) и от размера выборки или . То есть, таким образом, чем менее разбросан признак генеральной совокупности, и чем больше у нас размер выборки, тем меньше наша ошибка репрезентативности.
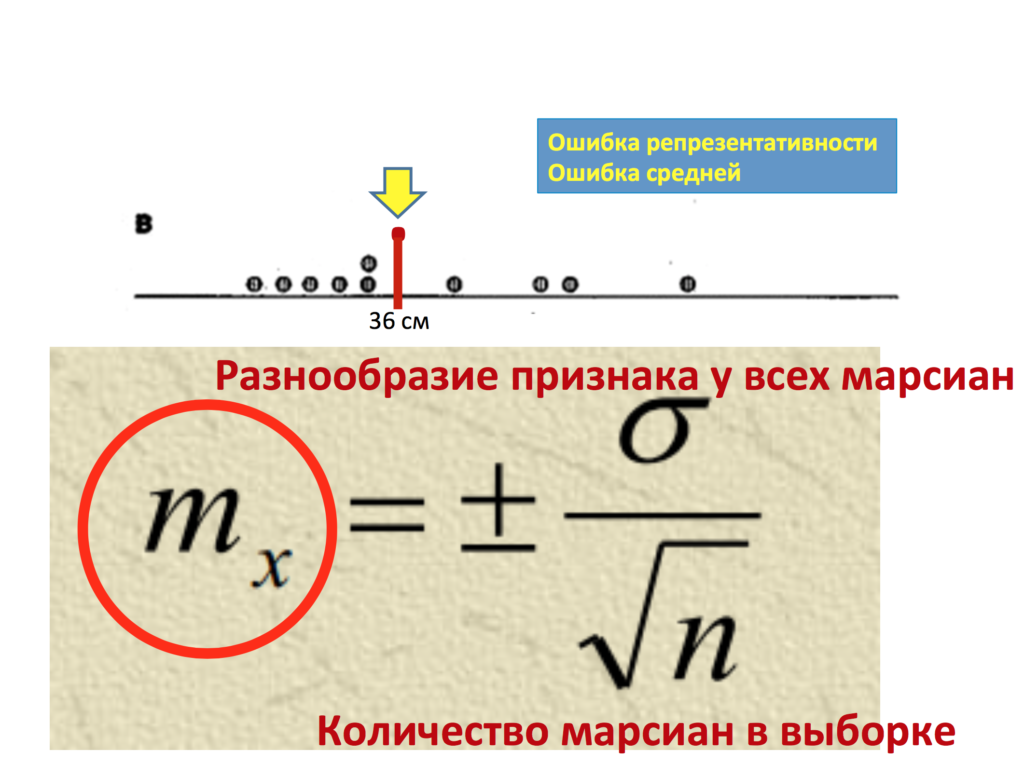
Итак, предположим, мы нашли нашу ошибку репрезентативности mr. В данном случае она составила 2,7 сантиметра. Но что же это нам дает? А дает нам это уже достаточно много. Теперь мы, зная, насколько в принципе наша выборка может ошибаться относительно генеральной совокупности, можем составить определенное предположение о том, где же находится реальный параметр – реальные 40 сантиметров генеральной совокупности на основании данных лишь нашей выборки.
Каким же образом это происходит? Мы провели точечную оценку нашего параметра. Дальше происходит второй этап построения доверительного интервала – это интервальная оценка параметра. Каким же образом строится этот интервал? А складывается он из 2 вещей: так называемой предельной ошибки +∆ и -∆. Формула нахождения предельной ошибки достаточно проста и составляет:
±∆ = t*mr
Для того, чтобы не залезать в критерий Стьюдента сегодня, я скажу лишь, что:
для доверительного интервала 95 % используется t=2,
для доверительного интервала 99 % используется t=3
и для доверительного интервала 68 % используется t=1.
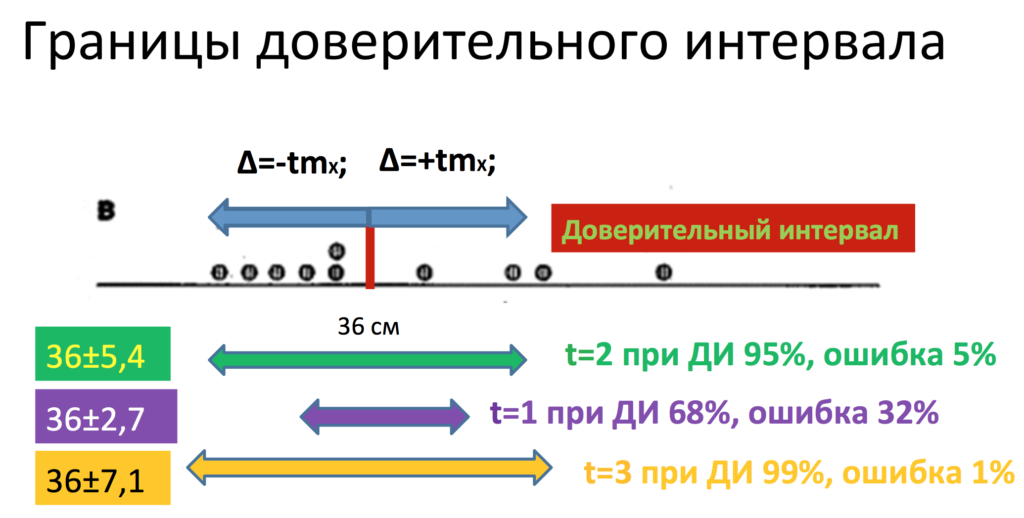
Итак, после того, как мы нашли нашу предельную ошибку, мы можем построить доверительный интервал. Но для этого нам нужно самим задать тот доверительный интервал, который для нас подходит больше всего. Чаще всего в медицине используется вероятность ошибки 5 %, то есть доверительный интервал 95 % или вероятность ошибки 5 % (р=0,05, р=5 %).
Что же значат эти 95 %? А значат они следующее, что с 95%-ной вероятностью в нашем интервале лежит реальное значение, и лишь в 5 % случаев мы ошибаемся. То есть в нашем конкретном случае наша ошибка репрезентативности составила 2,7 сантиметра. Предельная ошибка отсюда будет равна чему? Именно 5,4 сантиметра, то есть доверительный интервал, так как здесь и плюс, и минус, то есть нам нужно ошибку умножить на 2, составил 10,8 сантиметров. А именно наши 38 см±5,4 см. Ширина всего доверительного интервала составляет 10,8 см. Напомню, что он складывается из положительной и отрицательной предельных ошибок вокруг нашей выборочной средней.
Итак, говоря о доверительном интервале, нужно сделать ряд важных выводов.
- Во-первых, доверительный интервал относится к выборочной совокупности. Он показывает, насколько параметры из выборочной совокупности могут отличаться от реально существующих данных в генеральной совокупности. Насколько мы ошибаемся при формировании той или иной выборки, мы закладываем в так называемую ошибку репрезентативности, в ошибку средней и вокруг нее собственно и строим доверительный интервал.
- Ширину доверительного интервала задает собственно сам исследователь, варьируя тот критерий t, который он принимает в качестве необходимого. Чаще всего применяется t=2, которое и соответствует ширине доверительного интервала 95 %. 95 % означает, что с 95%-ной вероятностью действительно вокруг выборочной средней существует определенный доверительный интервал, в который и попадает реально существующая средняя из генеральной совокупности. Этот доверительный интервал может быть либо уже, если t=1; либо шире, если t=3.
- Доверительный интервал задается самостоятельно исследователем. Чаще всего он равен 95 %.
Если это видео оказалось Вам полезным, оно хотя бы немного раскрыло тайны доверительного интервала, ставьте лайки, подписывайтесь на наши рассылки и в комментариях пишите, какие темы по биостатистике вам бы были интересны для следующих выпусков. На этом я с вами прощаюсь. Меня зовут Кирилл. Пока!
